
Gitマスターへの道 part1 概要・仕組み編
04/18 2020
はじめに
本記事はプログラミングがある程度できてGitを何となく使っている、あるいはこれから使おうとしている人向けです。 とりあえずGitを使ってみたいという人には向きません。
昨今のソフトウェア開発において、チームで開発するならGitからは逃れられないでしょう。 個人開発においても秩序を持って中規模以上の開発をするなら、バージョン管理システムは必須ですので、 Gitをマスターしておけばきっと役に立つ機会があるはずです。
バージョン管理システム
原始的なバージョン管理はファイルのコピーに日付やバージョン名を付けて保存するというものです。 まあしかしこの方法はミスが多いよなーってことで作られたのが、バージョン管理システム(VCS: Version Contorl System)です。 多くのバージョン管理システムはだいたい以下の機能を備えます。
- 編集履歴の確認
- 過去の状態に戻す
- 複数人での管理
- バージョンの分岐
古いファイルや差分を参照できるので、例えば後で使うかもしれないと思ってコメントアウトしたりする必要も無いですね。
分散型バージョン管理システム
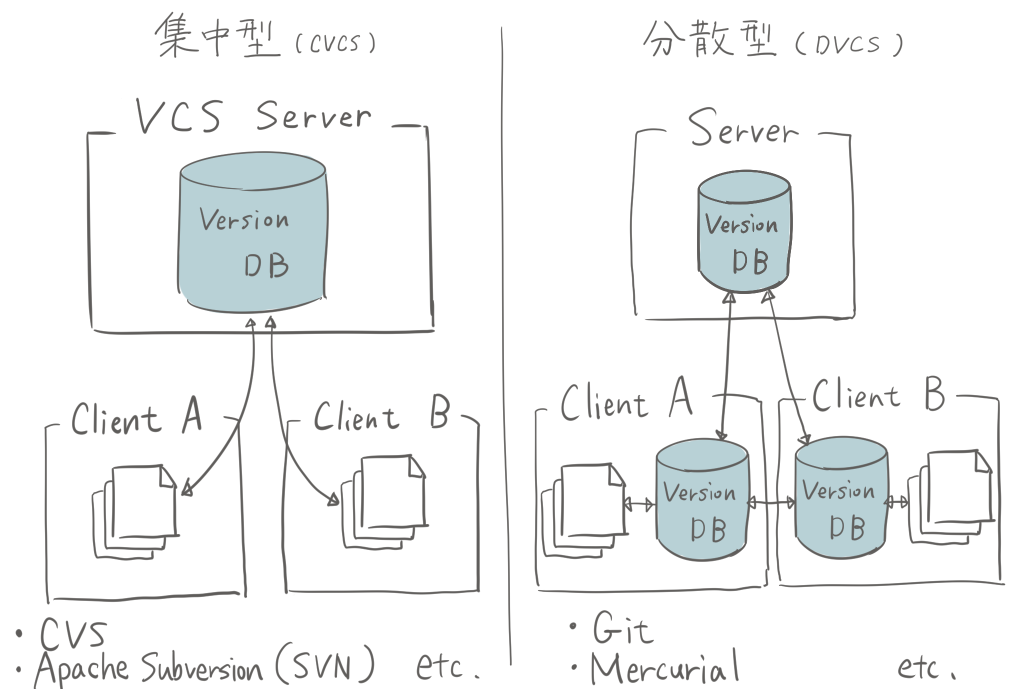
バージョン管理システムの分類のひとつに、集中型か分散型かがあります。Gitは分散型です。
集中型バージョン管理システム(CVCS: Centralized Version Control System)は、複数の開発者で協力して開発するために作られました。 CVCSの弱点は、サーバが無いと機能しない点です。例えばサーバがダウンしてしまうと、ダウンしている間は変更の保存や版を戻すといった操作は全くできません。 それに版管理の度にネットワークに接続する必要があるので、ローカル操作に比べて処理に時間がかかって利用にストレスがかかってしまいます。
分散型バージョン管理システム(DVCS: Distributed Version Control System)では、リポジトリをミラーリングします。 分散型はローカルだけでも動作するので、ネットワークに繋がっていない状態でも版管理ができたり、ローカルで版管理しながらいろいろ試せたりするわけですね。 また、集中型では実現できない階層型のような複雑で柔軟な構成を実現できるのも分散型の利点です。
Git is 何
GitはLinuxカーネルのソース管理のため、2005年に Linus Torvalds によって開発されたDVCSです。 Gitのコンセプトは以下の通りです。
- 処理速度
- シンプル設計
- 並列ブランチサポート
- 完全な分散
- 大規模プロジェクト
個人的には、どんどんブランチを切って、手元で手軽に変更を試して、良い変更ができたら適用するという操作が 高速にできる点がGitの良いところだと思います。
Gitの仕組み
僕はGitの使い方よりも先に仕組みから学ぶべきだと思っています。 シンプルなGitの設計に対して独特なコマンド体系を持っており、使い方≒コマンドを先に学ぶのは無駄が多いというか そっちの方が難しいと思います。
Gitリポジトリ
ローカルのgitリポジトリは.gitディレクトリ以下に保持されています。
(root)
┗ .git
┣ hooks/
┣ info/
┣ logs/
┣ objects/ (スナップショットのデータ)
┣ refs/ (ブランチ情報)
┣ config
┣ description
┣ HEAD (現在のブランチへの参照)
┗ index (ステージングエリアの情報)
Gitオブジェクト
Gitはデータを.git/objects/以下にGitオブジェクトとして保存しています。
Gitオブジェクトは3種類あります。
-
commit
- 版に相当する概念 ある時点のスナップショット
-
tree
- ディレクトリ
-
blob
- ファイル
Gitはこれらのオブジェクトをzlib圧縮したものを.git/objects/以下に保存しています。
例えば、以下の構造を持つディレクトリをGit管理下に置いてみます。
(root)
┗ citrus
┗ tangerine.txt
$ git init
$ git add .
$ git commit -m "add tangerine.txt"
するとgit/object/以下には4つのGitオブジェクトが生成されます。
$ find .git/objects -type f
.git/objects/6e/fe757d95c33b009a249558711bae5d6e2f17be
.git/objects/81/2365705c57b0a34c063671b6cef971c1576195
.git/objects/96/fc9594b530ec409b0d754c238ec6632e3f24c0
.git/objects/b6/1abd7ac74d2545b4ecfc2fced85060f4b76d80
それぞれのGitオブジェクトのファイル名はオブジェクトのsha1ハッシュになっています。 Gitのシステムはsha1ハッシュをオブジェクトのIDとして管理しています。
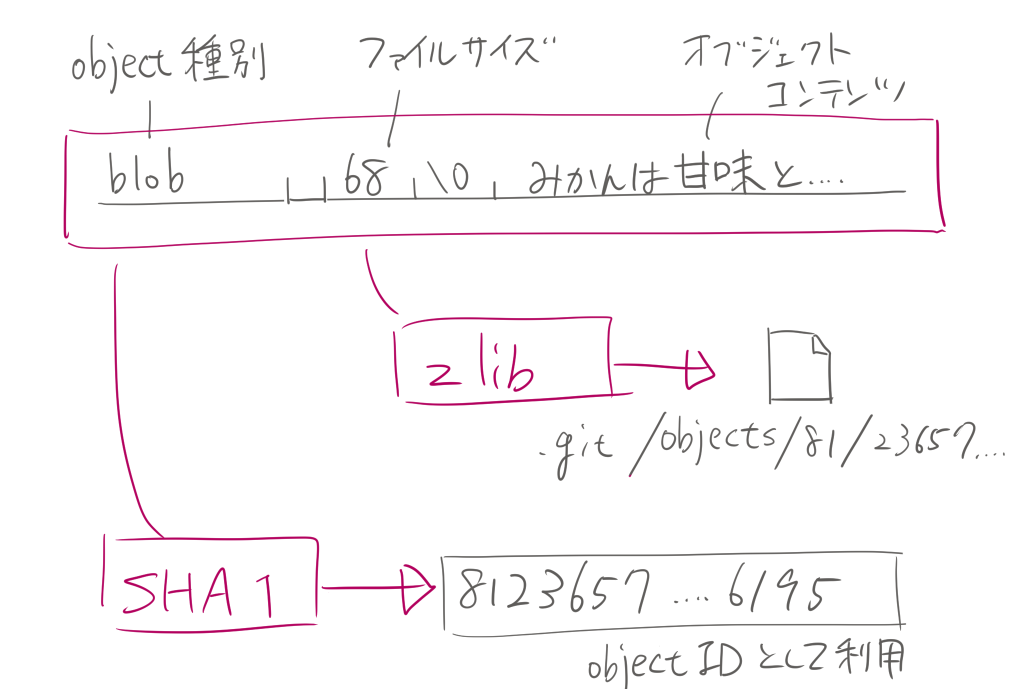
blob
blobはファイルの本文を保持します。 上記の例ではファイルはひとつなので、ひとつだけblobオブジェクトが生成されます
# cat-file -t はGitオブジェクトの種類を表示する
$ git cat-file -t 8123657
blob
# cat-file -p はGitオブジェクトの中身を表示する
$ git cat-file -p 8123657
みかんは甘味と酸味のバランスが良い果物です。
tree
treeはディレクトリの情報を保持します。 上記の例ではルートディレクトリとcitrusの2つのtreeオブジェクトが生成されます
$ git cat-file -t 6efe757
tree
$ git cat-file -t 96fc959
tree
$ git cat-file -p 6efe757
040000 tree 96fc9594b530ec409b0d754c238ec6632e3f24c0 citrus
$ git cat-file -p 96fc959
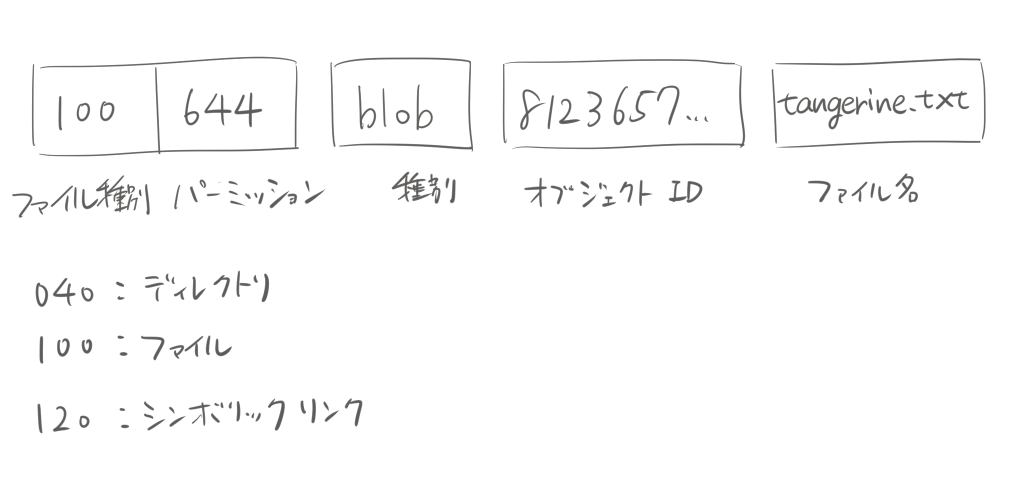
100644 blob 812365705c57b0a34c063671b6cef971c1576195 tangerine.txt
treeオブジェクトは1つ以上の他のオブジェクトへの参照と、参照のファイル名またはディレクトリ名が含まれます。
ここでtangerine.txtをコピーしてtangerine_copy.txtを作成してcommitすると次のようなtreeオブジェクトが生成されます。
$ cp citrus/tangerine.txt citrus/tangerine_copy.txt
$ git add .
$ git commit -m "create copy of tangerine.txt"
$ $ git cat-file -p 4d51ba2
100644 blob 812365705c57b0a34c063671b6cef971c1576195 tangerine.txt
100644 blob 812365705c57b0a34c063671b6cef971c1576195 tangerine_copy.txt
同一内容のファイルならblobのハッシュは同一になるので新しいblobオブジェクトは生成されないわけですね。
commit
commitは版に相当する概念です。Gitは版を差分ではなくスナップショットとして保存しています。1 commitにはrootディレクトリを表現するtreeオブジェクトの参照、0個以上の直前のコミットオブジェクトの参照、コミット日時、コミッター、コミットメッセージの情報が含まれます。
$ git cat-file -t 64ef796
commit
$ git cat-file -p 64ef796
tree 01dd654c1c1063551cae637dcdbae89df9d7cf97
parent b61abd7ac74d2545b4ecfc2fced85060f4b76d80
author Hassaku <xxx@example.com> 1587200406 +0900
committer Hassaku <xxx@example.com> 1587200406 +0900
create copy of tangerine.txt
直前のコミットオブジェクトの参照が含まれるので、これで過去が辿れるわけです。
ここまでのオブジェクトの状態を纏めるとこうなります。コミットがスナップショットであることがわかります。
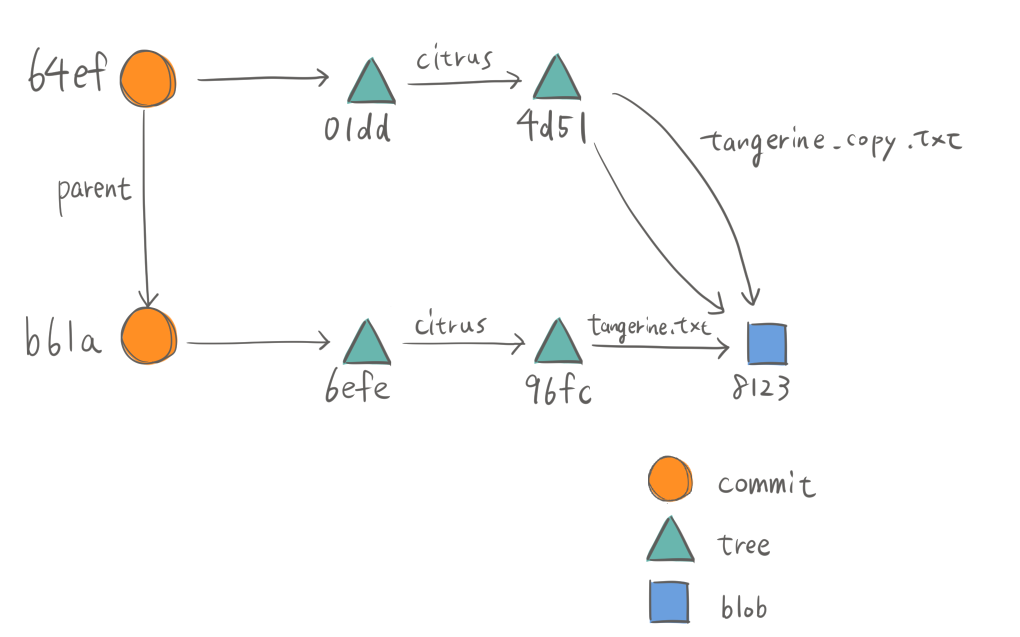
ブランチ
Gitには版を枝分かれさせるためのブランチという概念があります。
Gitのブランチはcommitオブジェクトへの参照です。デフォルトではmasterという名前のブランチが作られ、
.git/refs/heads/masterにファイルとしてcommitへの参照が記録されます。
$ cat .git/refs/heads/master
64ef796c799cc4f961681374488eb5a09af09328
$ git cat-file -t 64ef796
commit
# gitコマンドではコミットIDの代わりにブランチ名が使える
$ git cat-file -t master
commit
また、カレントブランチという概念があり、現在のブランチを.git/HEADに記録しています。
$ cat .git/HEAD
ref: refs/heads/master
ブランチの生成は単なる参照の生成です。
# HEADに対してsecondブランチを作成する
$ git branch second
# ブランチを一覧する
$ git branch
* master
second
$ cat .git/refs/heads/second
64ef796c799cc4f961681374488eb5a09af09328
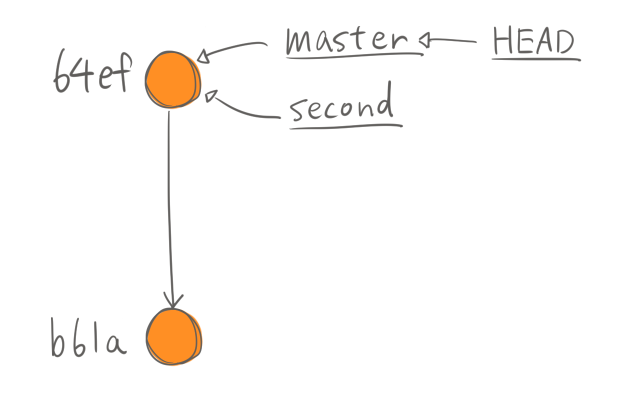
コミットすると、新しいcommitオブジェクトを生成してHEADのブランチの参照先を新しいコミットに付け替えますので、 分岐を作ることができるようになります。
# 現在はmaster
$ git branch
* master
second
# 新しいコミットを生成するとmasterの参照先が変わる
$ git commit --allow-empty -m "empty commit to master"
# コミットの履歴を表示
$ git log --oneline
294a7b0 (HEAD -> master) empty commit to master
64ef796 (second) create copy of tangerine.txt
b61abd7 add tangerine.txt
$ cat .git/refs/heads/master
294a7b067d9d56266003eaa1aea17b0d64f76291
# カレントブランチをsecondに切り替える
$ git checkout second
# 新しいコミットを生成するとsecondの参照先が変わる
$ git commit --allow-empty -m "empty commit to second"
# コミットグラフを表示
$ git log --all --oneline --graph
* 34bdb91 (HEAD -> second) empty commit to second
| * 294a7b0 (master) empty commit to master
|/
* 64ef796 create copy of tangerine.txt
* b61abd7 add tangerine.txt
$ cat .git/refs/heads/second
34bdb91d9133f29cb28eb1c4192f3085b6b13ee6
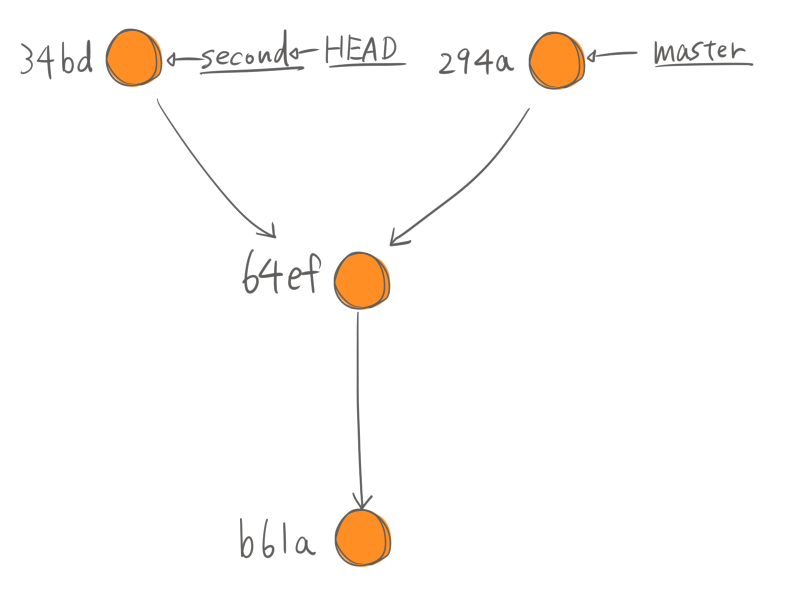
ここまで見てわかる通り、Gitはブランチの生成にほとんどコストがかかりません。 なのでどんどん分岐して実装を試してみることができます。
ステージングエリア
Gitはワーキングツリー(作業ディレクトリ)、ステージングエリア、Gitオブジェクトの3領域を使うことで、
柔軟なバージョン管理を実現しています。ステージングエリアの情報は.git/indexにblobオブジェクトへの参照として記録されています。
# ステージングされているファイルの一覧を取得する
$ git ls-files --stage
100644 812365705c57b0a34c063671b6cef971c1576195 0 citrus/tangerine.txt
100644 812365705c57b0a34c063671b6cef971c1576195 0 citrus/tangerine_copy.txt
各コマンドがどのようにステージングエリアを利用しているか知っておくことで、コマンドを利用するときに混乱せずに済みます。 例えば、addは指定したファイルをステージングエリアに記録し、commitはステージングエリアに記録されているファイルをコミット対象としてcommitオブジェクトを作成し、 checkoutは(必要ならばステージングエリアの内容を更新して)ステージングエリアに記載のblobをワーキングツリーに展開します。
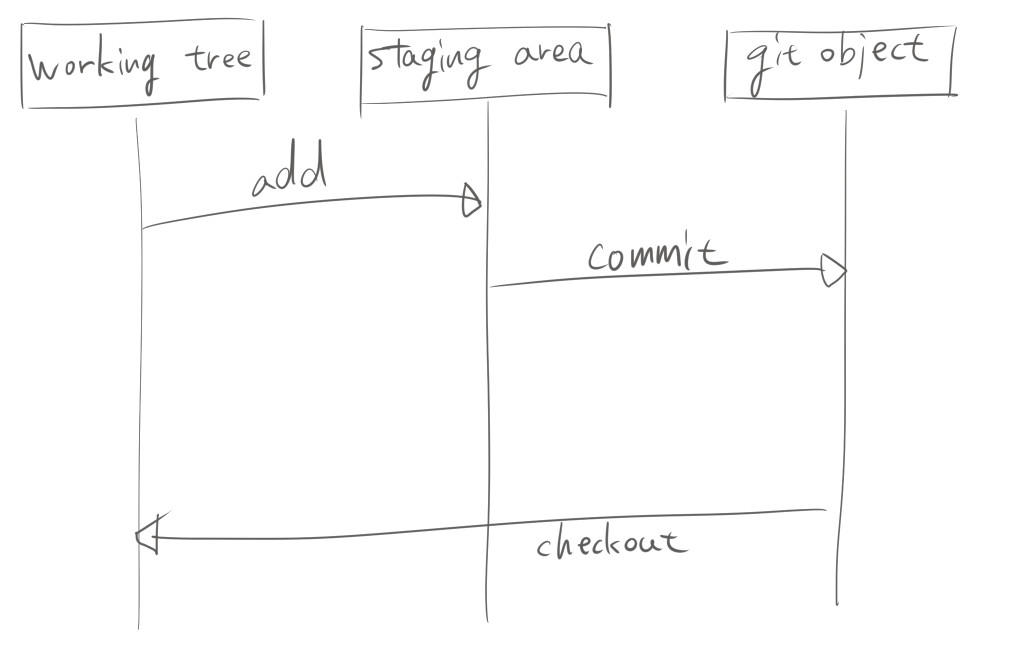
特にresetやコンフリクト発生時にステージングエリアがどういう挙動をするかを知っておくと大変捗ります。
おわりに
Gitに興味があるならGit - Bookにもっと詳しい内容が書いてあるので、 満足できないならこちらを読むといいですよ。
次回は各コマンドがどういう挙動をしているのかを解説予定です。
-
実際には差分を格納することでリポジトリを圧縮する仕組みがあります。スナップショットだけだと、どんどんリポジトリサイズが膨らんでしまいますからね。
↩